
The AI Context Skyscraper
A guidebook to mastering the architecture of context

For AI, great answers come from more than great questions. They come from great context. The right context includes the guardrails, historical data, environmental information, and guidance that turn raw outputs into real insights.
But while “context engineering” is an up-and-coming discipline in enterprises adopting AI, they’re often looking at the context the wrong way – as an engineering task – instead of a strategic business asset. Context is the very soul of the current AI age enterprise; the architecture of how you want your business to operate. Expecting engineers to engineer context alone is like a carpenter making cabinets without a blueprint for where they belong. Enterprise Context Management (ECM) is a rising enterprise software category that helps capture, curate, and deploy context at the right time and right place.
But to use context effectively, a new mental model is needed: The AI Context Skyscraper.
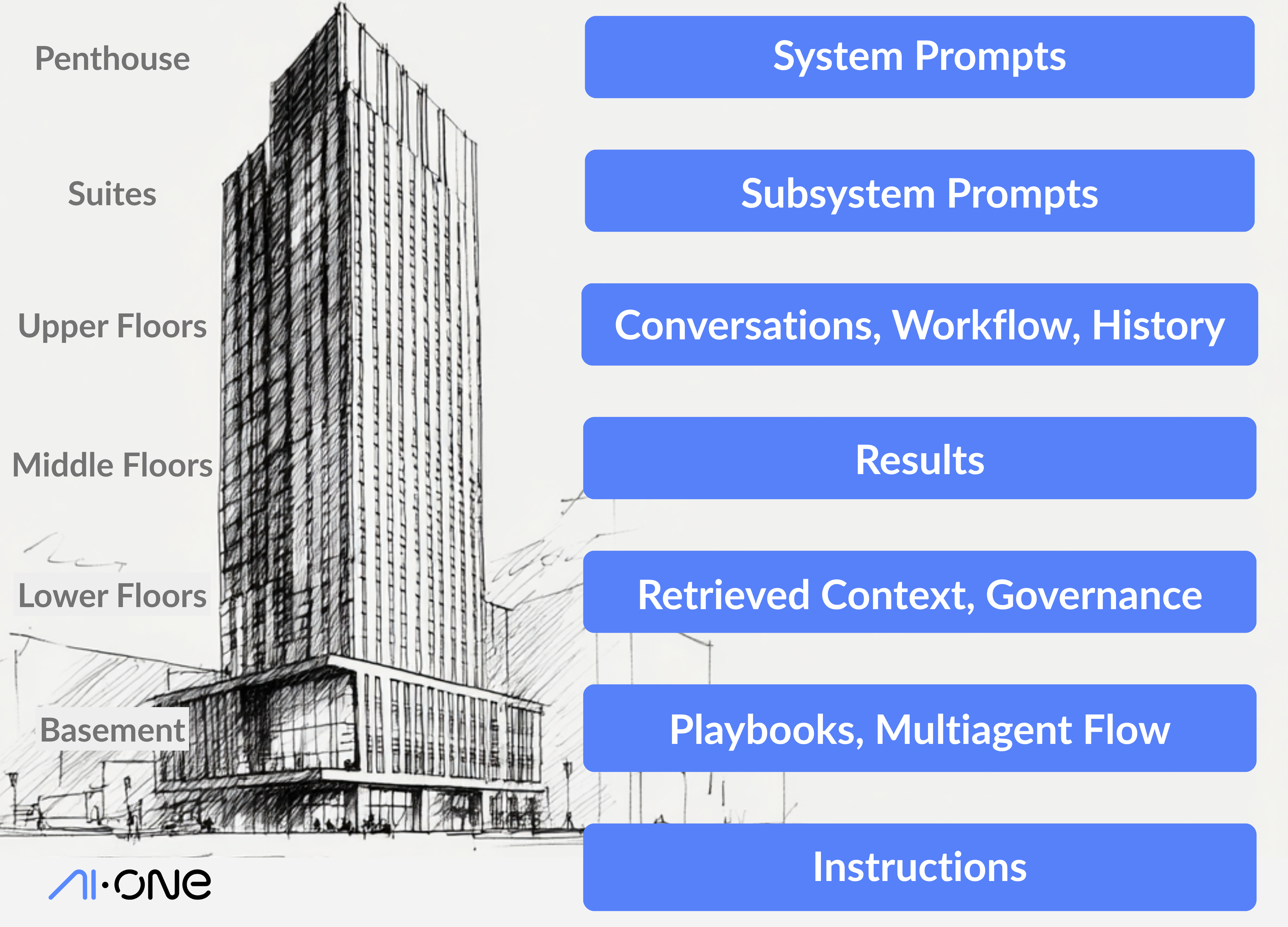
Context as Architecture
Instead of a single, undifferentiated block of text, imagine the context you provide to an LLM as a skyscraper, with each floor representing a different layer of information: corporate strategy on the top floor, customer interactions in the middle, and reusable recipes traveling by elevator from floor to floor.
The architecture of context is as important as the context itself. The position of each floor matters. The order, organization, and optimization of this context directly influences the LLM’s focus and the quality of its output.
Let’s explore this context skyscraper for FinCorp, a global financial services company, moving from the penthouse to the sub-basement with concrete examples.
The Penthouse: System Prompts
At the top of our skyscraper sits the system prompt. This is the most privileged real estate, and LLMs usually pay the most attention to what appears here, making it the core of the AI’s identity and objectives. This is where you define AI’s personality, style, and the fundamental principles that govern its behavior.
FinCorp’s system prompt might read:
“You are an assistant specializing in long-term financial advice and wealth management, maintaining a conservative approach to risk.
Ensure that all recommendations are tailored to each client’s specific goals, comply with SEC regulations, and align with our distinct investment principles and current market outlook. Prioritize accuracy over speed in every response, and always cite reliable sources.
After each recommendation, validate that the advice aligns with the client’s objectives, regulatory standards, and the latest market data; self-correct or escalate if there are any uncertainties. If uncertain about any information or recommendation, escalate the query to human oversight rather than offering speculative advice.”
System prompts, like penthouse residents, are your anchor tenants. They must be carefully curated, tested for suitability, then locked down. They represent your AI constitution. Your strategic north-star. Your principles. System prompts are treated with the reverence that position demands.
The Executive Suite: Subsystem Prompts
Just below the penthouse are subsystem prompts. This is your role identifier, the place where you specify the AI’s role for a specific set of tasks. It’s where the AI gets marching orders from your Chief Revenue Officer, Chief Marketing Officer, or Chief Financial Officer to align overall strategy with functional execution.
For example, FinCorp’s CFO might guide AI used to detect fraud with a subsystem prompt like this:
“You are a fraud research assistant responsible for assessing transaction patterns for unusual behavior, potential regulatory violations, and areas of uncertainty.
Immediately flag any anomalies that deviate by more than three standard deviations from established baselines. For each flagged anomaly, provide a one-line validation and indicate the next research step or correction if needed.
Before performing in-depth research on transactions involving high-risk jurisdictions or entities on watchlists, state the purpose and the minimum information you will use.”
Executive suite context prompts occupy the space just below the penthouse, and are owned by functional leaders at the highest level. They command significant attention from the LLM, making it a powerful lever for shaping behavior when the penthouse is off-limits.
The Upper Floors: Conversations, Workflow, History
As we descend into the upper floors, we encounter day-to-day interaction context. An example of context at this level are prior responses in an ongoing user conversation: every relevant question asked, every answer given, every clarification sought.
FinCorp’s conversational history might contain:
User: “Show me Q3 revenue for the EMEA region”
AI: “Q3 EMEA revenue was $45.2M, up 12% YoY”
User: “How does that compare to APAC?”
AI: “APAC Q3 revenue was $38.7M, up 8% YoY. EMEA outperformed APAC by $6.5M”
User: “What’s driving the EMEA growth?”Conversational history is essential context, but it can become bloated quickly. This floor is a prime candidate for intelligent compression. You want to retain the essence of the conversation without overwhelming AI with every word that’s been exchanged, or including irrelevant distractions
Summarization techniques work well here, allowing you to preserve the narrative arc and key information while reducing the token footprint. The compressed version might become: “User is analyzing Q3 regional performance, specifically comparing EMEA ($45.2M, +12% YoY) vs APAC ($38.7M, +8% YoY), now investigating EMEA growth drivers.”
In addition to conversations, the upper floors also house the context of workflows. Workflows include the steps AI takes to reason through complex questions, showing which tools have been called, in what order, and with what parameters. Workflow context provides an audit trail and can be refined to build organizational wisdom for answering complex questions.
FinCorp’s question could require these steps:
Called Salesforce (Table=“revenue”; Filter=“Region”, EMEA, quarter=Q3)
Called Salesforce (Table=“revenue”; Filter=“Region”, APAC, quarter=Q3)
Called Database Calculate Variance(45.2, 38.7)
Next: Analyze Growth Drivers (Region=“EMEA”, quarter=“Q3”)When crafting this context, prune irrelevant steps but maintain the sequence of actions. This floor provides the AI with a sense of what has been tried, what worked, and what didn’t, enabling more intelligent decision-making about next steps.
The Middle Floors: Results for Explainability
The middle section of our skyscraper houses some of the most critical and untouchable content: the raw output from relevant API calls, database queries, or data returned by external systems. This context provides the raw ingredients for explainability in AI. The ground truth. The audit trail. Result sets should rarely be optimized, compressed, or summarized by automated processes, only logged.
Raw output is the factual foundation upon which the AI’s reasoning is built, and any corruption of this data could lead to catastrophically wrong conclusions and the erosion of trust and verifiability in outcomes.
A database query might return:
{ “query_id”: “rev_q3_emea”,
“timestamp”: “2024-10-15:23”,
“results”: [
{”country”: “Germany”, “revenue”: 18500000, “yoy”},
{”country”: “UK”, “revenue”: 14200000, “yoy”},
{”country”: “France”, “revenue”: 12500000, “yoy”}],
“records”: 3}The logging of the precise technical question asked ensures errors, bias, and hallucinations can be understood, audited, and fixed.
Along with the calls made to AI, we preserve the results.
Building on this raw data, the middle floor may also contain any summary tokens that might be provided by the AI’s reasoning or chain of thought: its step-by-step progression of how it arrived at a recommendation. For example, FinCorp’s reasoning chain might have been:
User asked: “EMEA growth drivers”
Retrieved: Country Level (Germany (+15%), UK (+9%), France (+11%))
Observation: Germany represents 41% of EMEA revenue and has highest growth rate
Prediction: This suggests Germany is the primary growth driver
Next: Explore what changed in the German market in Q3The data from this floor should remain largely untouched, serving as the intellectual scaffolding of the AI’s decision-making process. Storing questions, results, and reasoning chains ensures you can always show your work and demonstrate how the AI arrived at its conclusions.
The Lower Floors: Retrieved Context and Governance
As we move into the lower floors, we encounter the next set of context for the question: the information retrieved from knowledge bases, vector databases, or other sources to help answer the current query.
When investigating EMEA growth drivers, the system might extract key facts from a knowledge base:
Germany Q3 2024: Launched new enterprise product tier in July
UK Q3 2024: Faced increased competition from local fintech startups
France Q3 2024: Expanded partnership with major retail bank, added 150 enterprise customers
EMEA Market Report Q3: Manufacturing sector had 18% increase in spendingRather than simply dumping results from a vector similarity search using RAG, a more sophisticated approach involves a “Context Loop”, which uses intelligent chunking and multiple similarity search passes on the raw underlying documents and data-sources, to explore the best match, drill down, and follow threads of relevance. Instead of taking a single retrieval pass, the Context Loop successively determines the best, most relevant, context. Context looping is particularly important when extracting context from numerous large documents, extensive database schemas, or complex knowledge graphs.
Below Context Loop-extracted context, we establish the guardrails, the hard rules, and the constraints that govern the AI’s behavior. These are non-negotiable boundaries: what data the AI cannot access, what actions it cannot take, and what topics it must avoid:
NEVER access or display individual customer names or personal identifiers
NEVER execute queries against production databases, only read replicas
NEVER recommend actions that would violate GDPR or data residency requirements
NEVER process or display salary information for identifiable individuals
MUST reject any request to bypass audit logging
MUST escalate to human oversight for any transaction >$1MThese guardrails are strictly enforced and should never be compressed or optimized away. They are the safety systems of your AI, the circuit breakers that prevent catastrophic failures.
Adjacent to the guardrails, we have conduct and expectations—a softer set of guidelines that shape the AI’s personality and communication style:
Maintain a professional, formal tone appropriate for financial services
When presenting numerical data, always include units and time periods
Acknowledge uncertainty rather than presenting speculation as fact
Provide context for percentages (e.g., “15% growth on a base of $18.5M”)
Use inclusive language and avoid regional bias when comparing markets
Cite data sources for all quantitative claimsUnlike the hard guardrails, these are more like cultural norms, shaping how the AI presents itself and interacts with users.
The Basement: Playbooks and Multi-Agent Integration
The basement of our skyscraper houses the playbook, a truly innovative feature. This is an LLM-populated guide that captures the accumulated wisdom from previous executions of similar workflows. Every time the AI successfully completes a task, it can contribute to this playbook, noting which strategies worked well and which approaches led to dead ends.
PLAYBOOK - Revenue Analysis Workflows
Pattern: Regional growth investigation
- Success strategy: Start with country-level breakdown
- Use: regional_sales
Pattern: EMEA analysis
- Avoid: Don’t rely on revenue table - it excludes partner channel sales
- Use: combined_revenue_view
Pattern: Growth driver identification
- Success strategy: Check for product launches
- Success strategy: Check for partnership announcementsThe playbook represents organizational learning at scale, turning every AI interaction into a source of competitive advantage. It’s how your AI gets smarter over time through the accumulation of procedural knowledge. When faced with a new instance of a familiar problem, the AI can consult the playbook to see what has worked before, dramatically improving its efficiency and success rate.
This floor should be carefully curated but not aggressively compressed. The insights here are valuable precisely because they contain nuance and detail. Strip that away, and you lose the very knowledge you’re trying to preserve.
Finally, we have space for input from other agentic frameworks. In a multi-agent system, where different AI agents handle different aspects of a complex workflow, this floor provides a clean integration point. It’s where Agent A can pass context and results to Agent B, enabling sophisticated orchestration without contaminating the other floors of the skyscraper.
This separation is crucial for maintaining clarity and debuggability in complex systems. When something goes wrong, you need to be able to trace the flow of information between agents, and having a dedicated floor for inter-agent communication makes that possible.
The Context Foundation Meets the Task At Hand
Underpinning all the prior context sits the prompt itself: the specific instructions for the current task.
First should come the original question that we are seeking an answer to. This is the user’s initial query that triggers the entire workflow. Even as the AI moves through multiple steps in an agentic loop, calling various tools and processing information, this original question serves as a north star.
“What’s driving EMEA growth?”
It’s the constant reference point that ensures the AI doesn’t drift off course, doesn’t get lost in the weeds of intermediate processing, and ultimately delivers an answer to what the user actually wanted to know.
Finally, we reach the current task. This is what the AI is being asked to do right now, at this moment. It needs to be clear, unambiguous, and immediately actionable.
“Using the country-level revenue data retrieved from the database, identify the top 3 contributors to EMEA growth in Q3. For each country, calculate its contribution to the overall regional growth and identify any significant product or customer segment changes. Present findings in order of impact magnitude.”
This is the AI’s current focus, the question it’s actively working to answer. It is at the bottom of the prompt due to something known as recency bias, where LLMs pay a little more attention to the most recent information it’s been given.
Some models will even improve their response if this is underlined with one repeated strata of instruction such as:
“Provide a ranked list of the top 3 EMEA countries driving Q3 growth, with each country’s % contribution and key product or segment changes. No commentary or extra text.”
This question-answering is where the context rubber meets the road, and it takes careful interplay with the LLM to keep it on task and context-aware.
The Fatal Flaw of One-Size-Fits-All Optimization
The tour of our skyscraper reveals the fundamental flaw in current context management: a one-size-fits-all approach to optimization. Most optimization techniques treat the entire context window as a single, undifferentiated mass. They apply the same algorithm to every floor of the skyscraper, often all at the same time.
This is architectural malpractice. It’s like trying to renovate a building by applying the same design to the penthouse, the boiler room, and every office in between. You wouldn’t insulate your lobby the same way you insulate your roof, and you shouldn’t optimize your tool results the same way you optimize your conversational history.
The list of optimization techniques available to apply to each floor is extensive, including some such as:
Query-focused Summarization
GEPA (GEnetic-PAreto Optimization)
ACE (Agentic Context Engineering)
Chain of Verification
Targeted Truncation and redaction
Self refine/Critique re-write
Instruction decomposition
Context salience labelling
Each floor has different requirements, different sensitivities, different roles in the overall structure. The system prompt needs to be protected and optimized once. Tool results should never be compressed. Conversational history can and should be summarized. The playbook needs careful curation. Guardrails must remain intact.
When you apply a blanket optimization strategy across the entire context window, each floor inherits the disadvantages of that approach. You end up compromising the integrity of the entire building, losing critical details like the one-time bonus in the France data while wasting tokens on redundant conversational history.
The Power of Floor-Specific Strategies
The alternative is to manage each floor independently, applying the optimization strategy that makes sense for that particular type of content, and for the LLM that you are targeting. This might mean using one compression technique for conversational history, a different approach for workflow history, and no compression at all for tool results and reasoning chains. A different LLM will require different optimizations for each floor, and even potentially move some floors around.
This granular control is not merely academic; it is a practical necessity for building robust, reliable, enterprise-grade AI systems. It allows you to maximize the effective use of your context window, preserving the most important information while still fitting within token limits. Flexible meta-optimization architectures enable switching from one LLM to another easily, eliminating single vendor dependencies. It enables you to maintain explainability and traceability where required, while still achieving efficiency where possible.
Moreover, this approach is fundamentally more flexible. As new optimization techniques emerge, you can adopt them selectively, applying them to the floors where they make sense without disrupting the rest of your carefully constructed context architecture.
Sovereign Context: Taking Back Control
The most important implication of the context skyscraper model is the concept of sovereign context. When you view context as a complex, multi-layered structure that requires sophisticated management, it becomes clear that you can’t afford to outsource this responsibility to third-party AI providers, or allow context to be applied in an ad-hoc manner.
Your context is not just data. It’s the distilled essence of your business, your processes, your institutional knowledge. It’s the competitive advantage that makes your AI uniquely valuable to your organization. When you hand control of that context over to a SaaS provider or a frontier LLM provider, you’re not just creating a security risk, you’re giving away strategic control.
Consider our FinCorp example. The playbook contains hard-won knowledge about data quirks, successful analysis patterns, and domain-specific insights. The guardrails encode your risk tolerance and regulatory obligations. The conversational history reveals your analysts’ thinking patterns and priorities. This is not generic, commoditized information; this is your institutional intelligence.
Sovereign context means building, managing, and owning your context skyscrapers. It means having the flexibility to fine-tune your context for specific tasks without being locked into a vendor’s optimization strategy. It means ensuring the security and privacy of your data by keeping it under your own roof.
In the same way that it’s unreasonable to expect a standardized skyscraper to fit into every city’s skyline, it is not realistic to expect a context window optimized for a specific model to generate the same results when thrown into a different model. Different LLMs and tools prefer different skyscraper “shapes” and techniques in order to provide the most accurate results.
The risk of optimizing a context window to work only for one model is to create a certain level of single vendor dependence that becomes undesirable in the future. The benefit of using a flexible, floor-based context optimization strategy is that it is trivial to create multi-vendor versions of everything, so you always have the right shaped building for the city you are building in.
Enterprises that treat their context as a first-class asset, as valuable as their data, code, and other intellectual property, will be the ones to thrive in the AI era.
Build Your Own Context Skyscraper
As you embark on your enterprise AI journey, adopt the mental model of the Context Skyscraper. Don’t think of context as a blob of text, think of it as a carefully architected building, with each floor serving a specific purpose and requiring a tailored management approach.
Build your skyscraper with intention. Understand what belongs on each floor. Apply the right optimization strategies to each level. Protect the floors that need protection, and optimize the ones that can afford it. And above all, never give away the keys to your building.
The context creation loop is where the real value of enterprise AI is unlocked: the continuous, iterative process of extracting context, managing it through your skyscraper, and using it to drive intelligent workflows. It’s the difference between AI that merely responds to prompts, and AI that truly understands and advances your business objectives.
The skyscraper is yours to build. Build it well, and you will unlock the true power of enterprise AI.
 | A guest post by
|
Love this post! Was just reading this related post about “Context engineering by hand” and they seem to be related in terms of the stack they propose and the “skyscraper” here. It’s interesting that they mention and include MCP as a layer at the lower level. : https://open.substack.com/pub/aibyhand/p/context-engineering-by-hand
Great post!
Wonderful article Mark - truly
enlightening